


GoEx: Mitigating the risk of LLM-generated output
A new paper designs a runtime for LLMs


The risk of LLMs
LLMs are evolving beyond their passive role. Today, LLM apps aren’t just mere chatbots answering your questions with pieces of text and code, but actionable agents that use LLM tools (often called functions or actions) to perform much more interesting tasks.
When I say “agent,” I’m referring to a self-sufficient assistant powered by LLM technology. I may use terms like LLM app or AI agent interchangeably.
For example, you can ask an LLM agent to analyze your favorite stock and create a price prediction chart from scratch. You can even give it some data and let the agent use it for analysis.
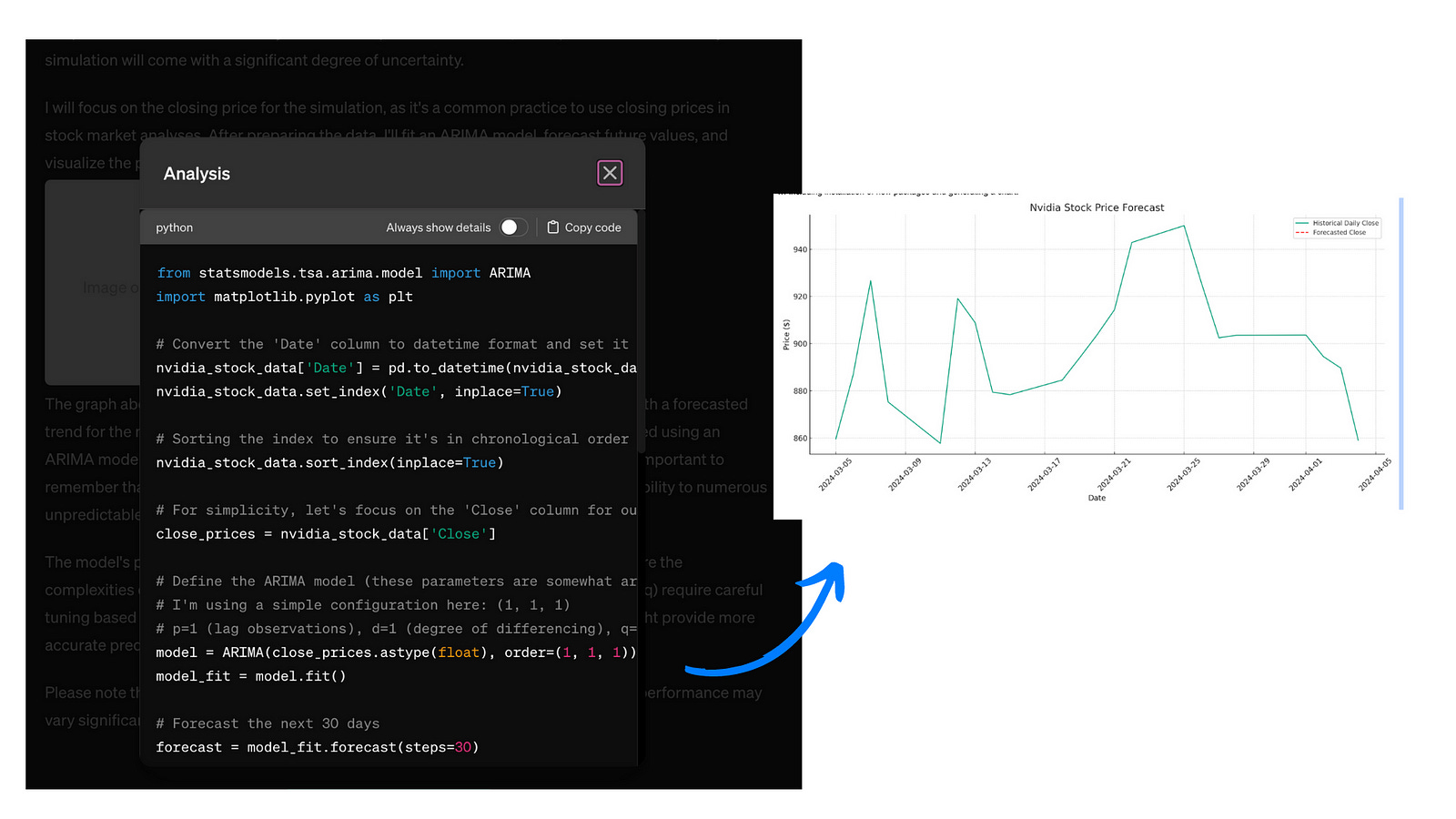
To compare LLM apps that are vs aren’t actionable, here, the agent on the left is able to execute an analysis for you, while the agent on the right just gives you advice on how you can do it yourself. (I gave them a task that requires running code — to do a binary search in Python with random data.)
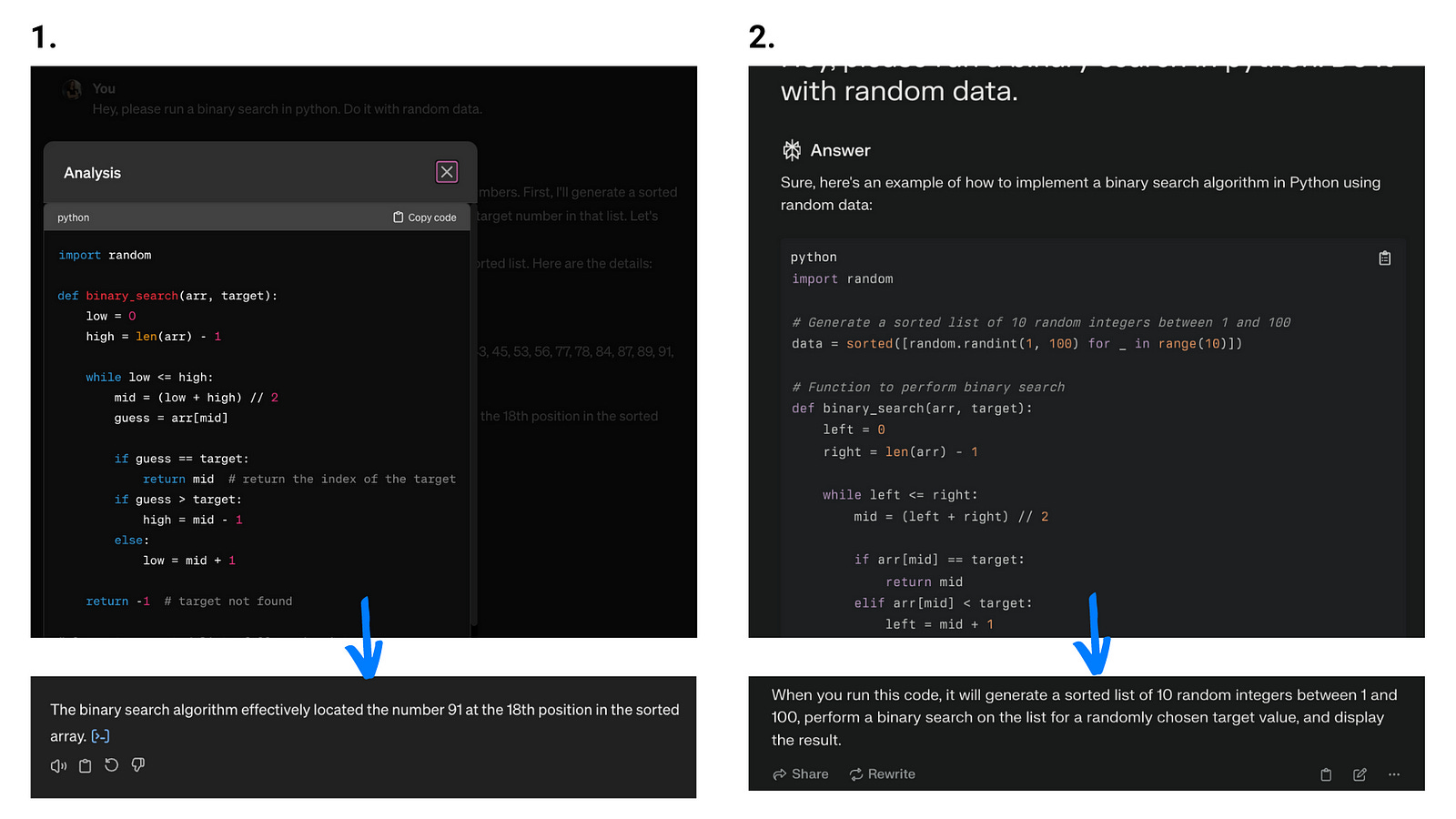
This, and other complex tasks, like working with your files, running programs, accessing your calendar, or sending emails for you often make the LLM do more steps. But since they still may not do exactly what you require, with each step, the level of risk adds up.
To summarize, these are some of the biggest challenges of LLM-powered apps:
Stochasticity — LLM won’t return the same response on the same prompt.
Unreliability — Difficulty of testing and monitoring LLMs behavior.
Hallucination — LLM tends to generate false information.
Snowball effect — With fewer human interactions, the small mistakes LLM makes might compound.
How do you mitigate the risk of such autonomous LLM agents doing something wrong or even dangerous on your computer?
The solution in the paper
A new paper called “GoEx: A Runtime for Autonomous LLM Applications” designed a (partial) solution to these problems.
It suggests that testing an LLM-generated output and potentially reverting it is easier than the “pre-facto validation” setting.
GoEx designed a runtime (an environment) for autonomous LLMs. They introduced a notion of “post-facto LLM validation”.
That means in their design of LLM agents, you as a user can check what the agents have done and decide whether it’s what you want. If you like the output, you proceed with it, if not, you reverse it with something like an “undo button”.
This is a different approach than trying to predict in advance what the agent is going to do or just creating a secure isolated environment for the agents' actions.
As an example, if you let an AI agent send a Slack message to one of your colleagues for you, there is an option to revert. See how the GoEx solution can look practically:
You might think… What if an action doesn’t have an undo?
For tasks like getting information from a website or sending an email, there really isn’t a reasonable reverse action.
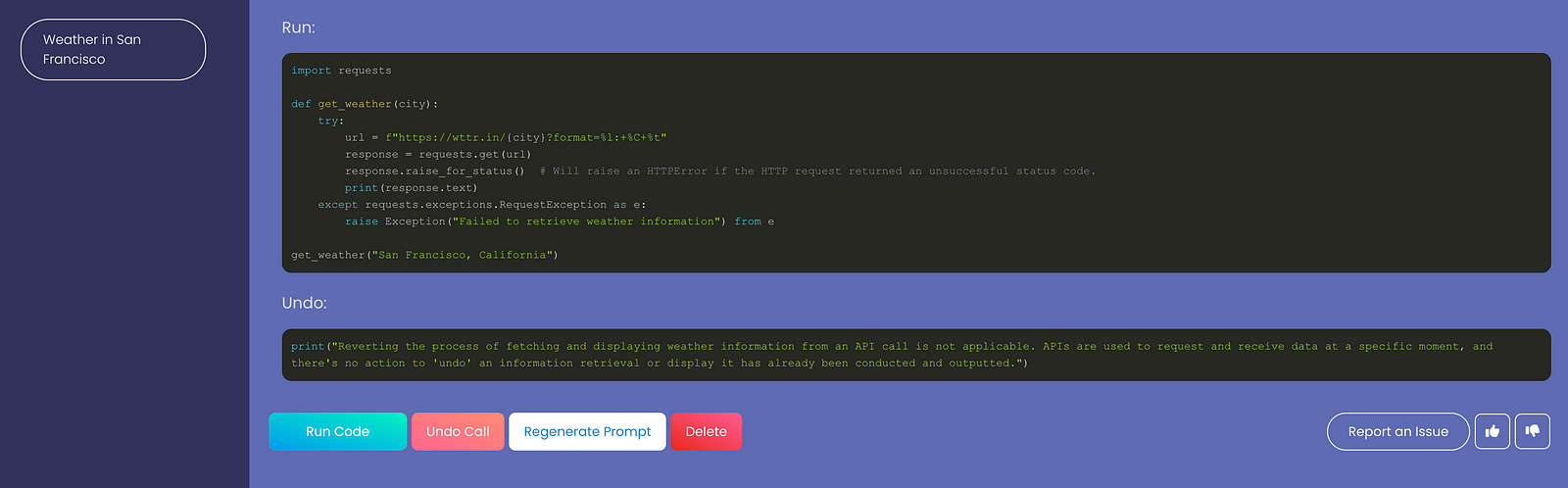
For such cases, GoEx offers “damage confinement” or “blast-radius confinement”. That means the user can qualify their risks and choose to be confident that the potential risk is bounded.
In this example from the GoEx web app, the agent was asked to share info about the weather. This obviously can’t be reversed, so you as a user have to evaluate whether you consider the risk of the agent doing something mischievous low enough.
Design of the runtime
I was indeed curious about what this runtime design looks like.
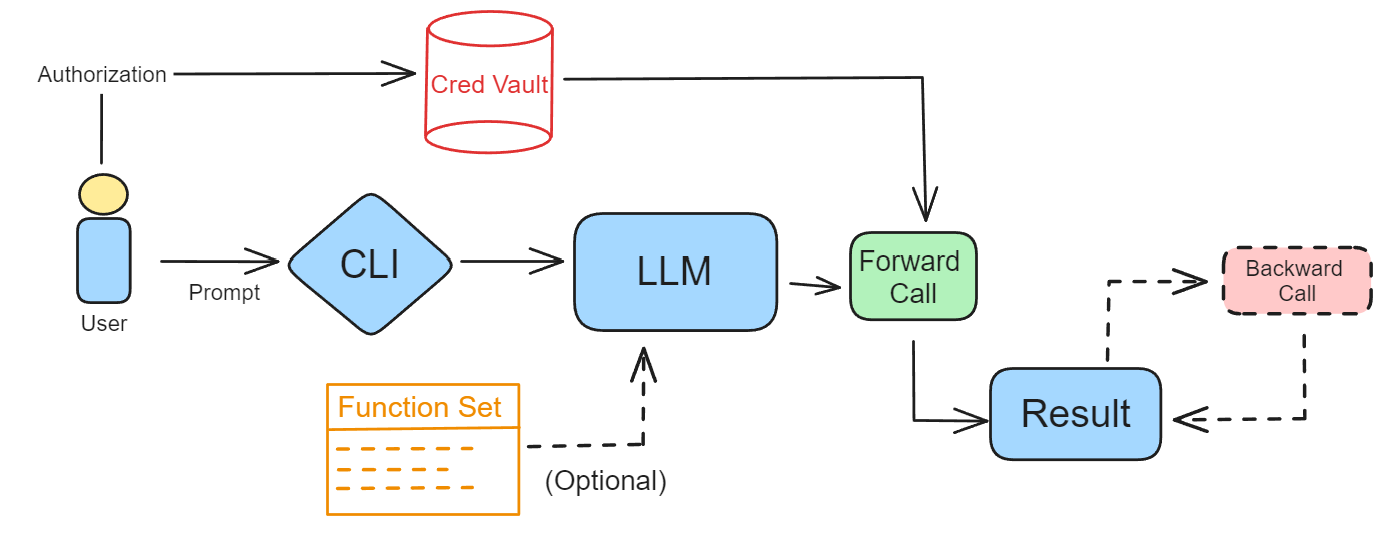
This is how GoEx sketched the mechanism of a human user writing a prompt, and LLM executing actions, with an optional backward call.
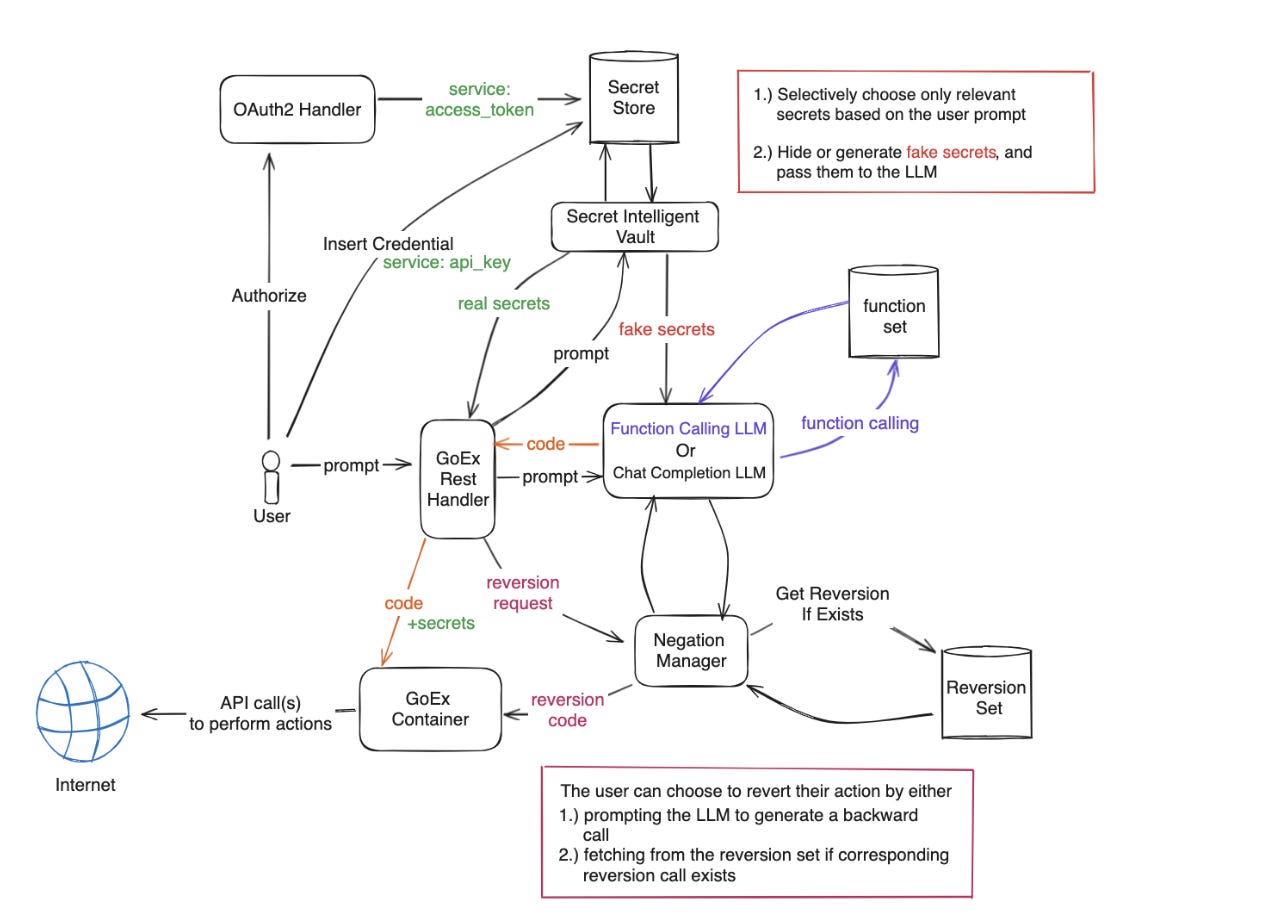
This type of mechanism is specifically for RESTful API calls — meaning that this is a scenario of what happens when the agent is using the internet, for example for searching for information. It might look complicated, but that’s just because it covers all the scenarios.
First, there are the reversion mechanisms for the undo actions.
Second, this design also handles authorization problems, using OAuth2 for token-based authentication or API keys for direct service access. User secrets and keys are stored locally on the user’s device in a Secret Intelligent Vault (SIV) — which has the role of selectively retrieving only those used for a given action.
Third, there are ways to treat irreversible actions. The blast-radius-containment is implemented through coarse-grained access control and exact string match. This is for checking what kind of authorization will be needed. (E.g. credentials for Slack vs for your bank). This helps the user evaluate the risk.
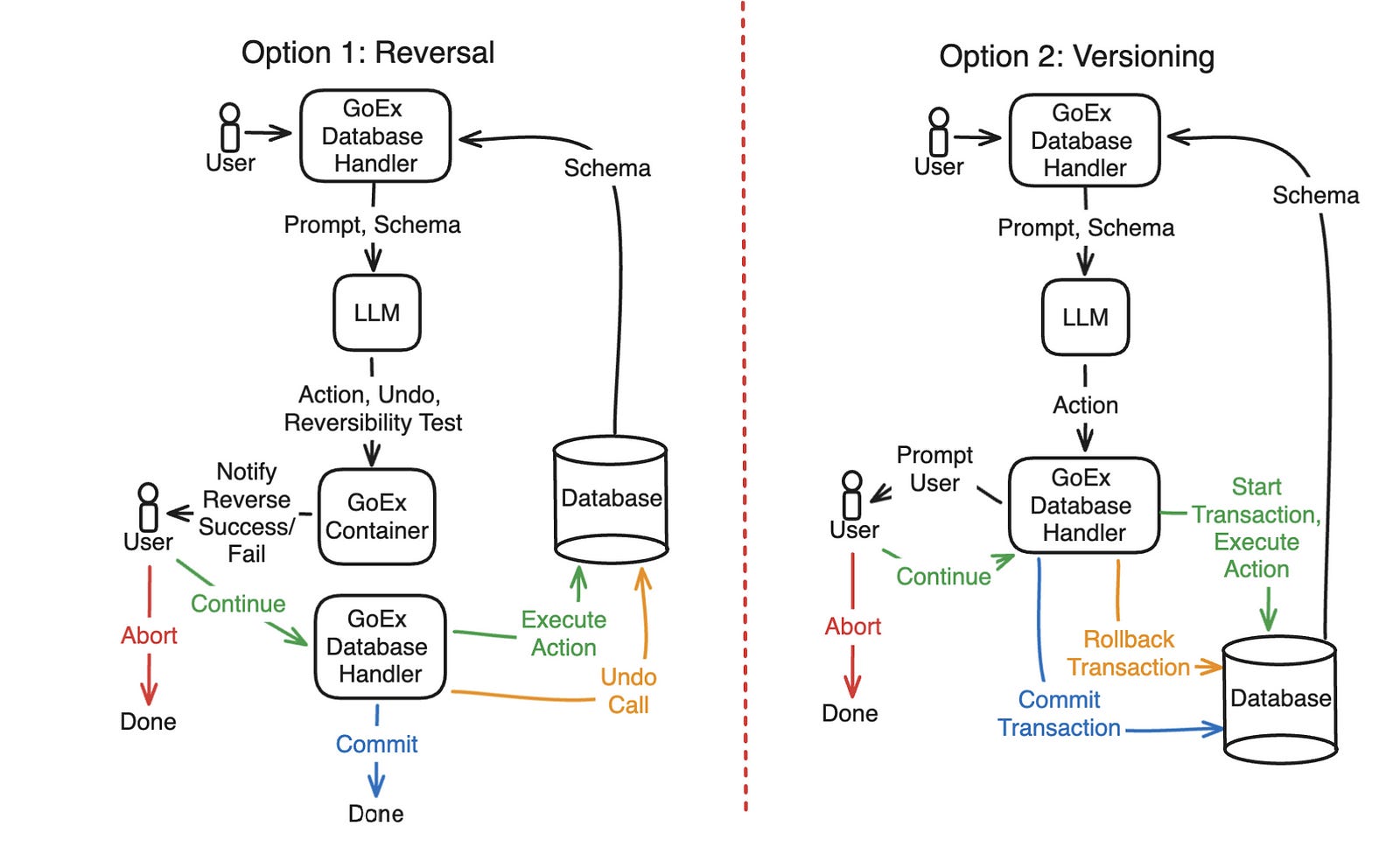
There are other types of tasks described, like actions on a database:
… Or a filesystem:
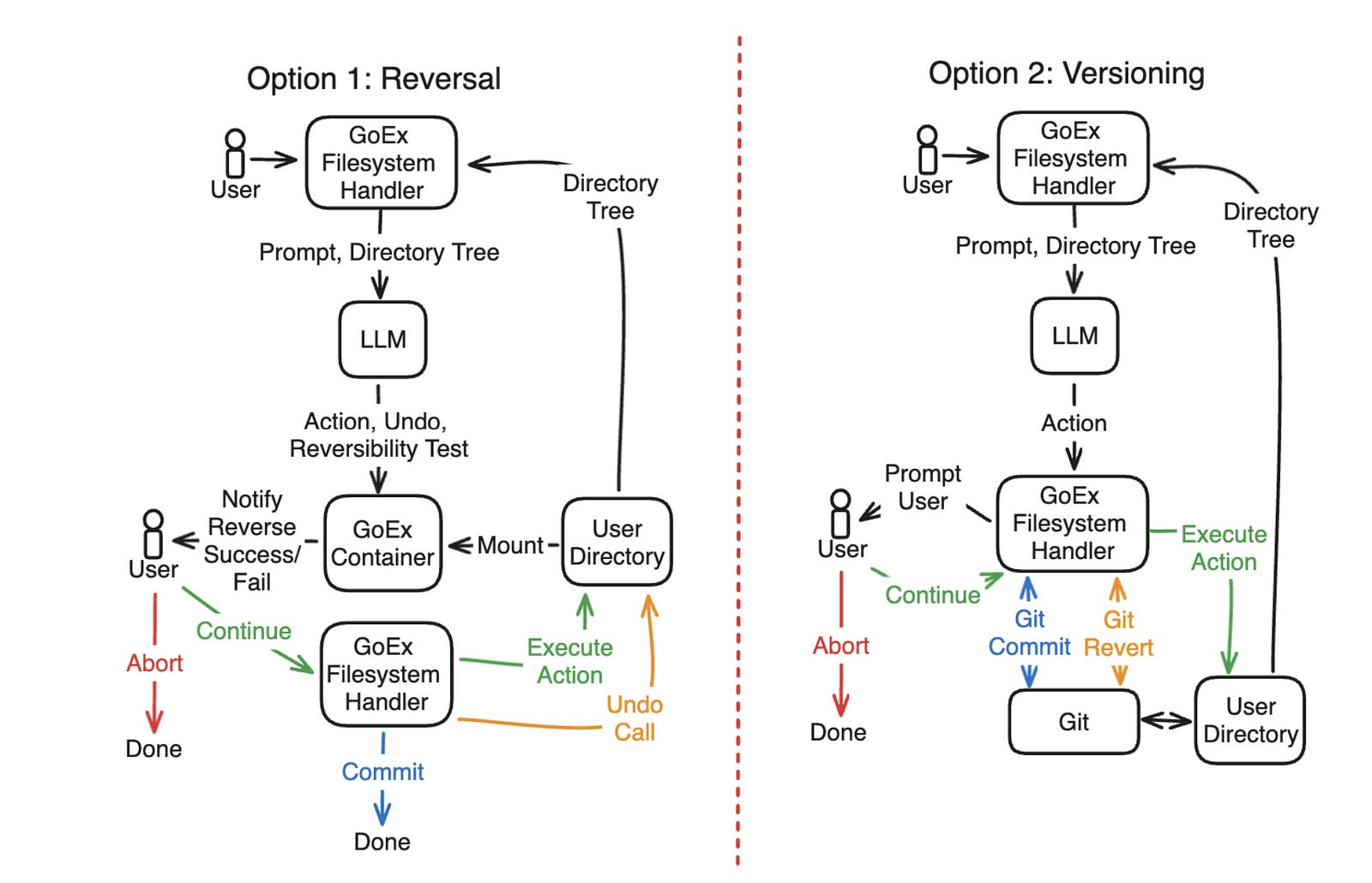
The reverse mechanisms differ for each specific use case, but the principle stays the same.
This is the design of the GoEx runtime, simplified:
The code
GoEx is open-source, so you can check the Python code.
One of the most important parts is the main.py with a class where they define the functions for reversal of different types of actions the LLM agent can take.
The program generates a pair of API calls and their reversals based on the input prompt, API type, credentials, and model.
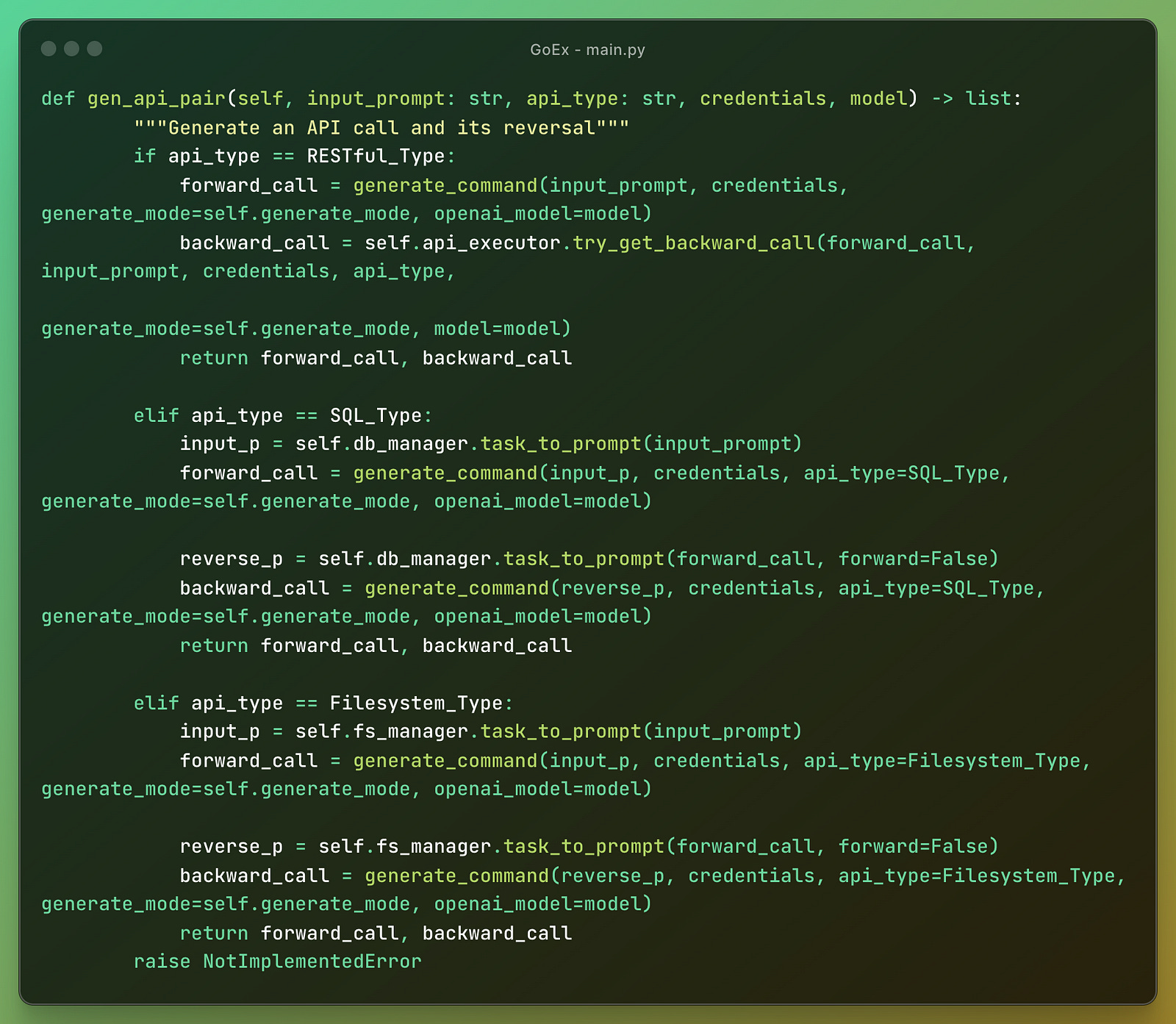
It generates and executes API calls along with their reversals.

Part of the solution is testing an API call and its negation by executing them in a sandbox environment and verifying the state reversion. This is done in a Docker container providing some level of security, especially for the actions that don’t have a suitable reverse action.
Docker is how also AutoGen or other agentic apps and frameworks deal with code execution.
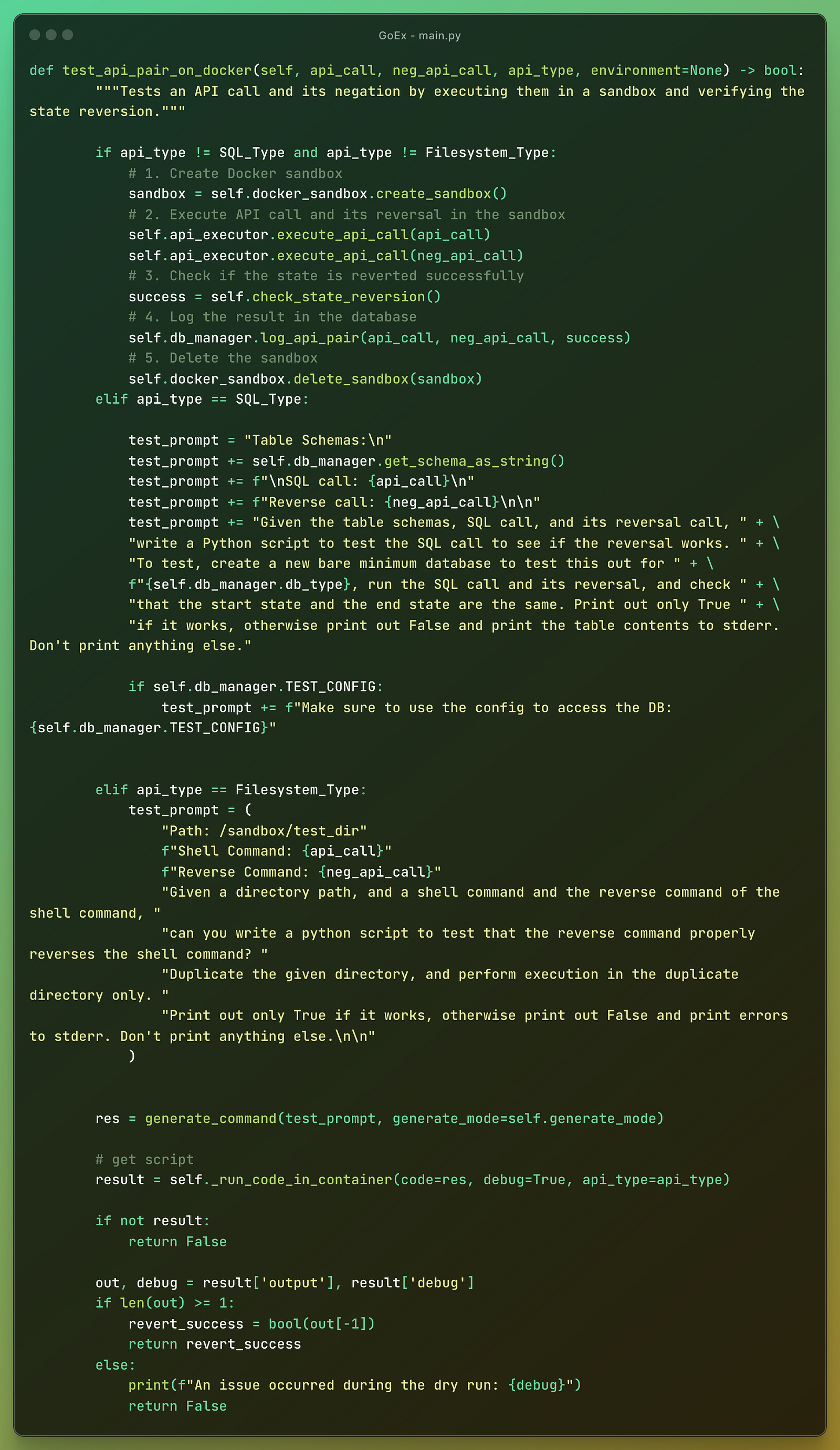
There are more functions defined to handle all the cases for the three types of actions that correspond to the diagrams above (RESTful API, databases, filesystem).
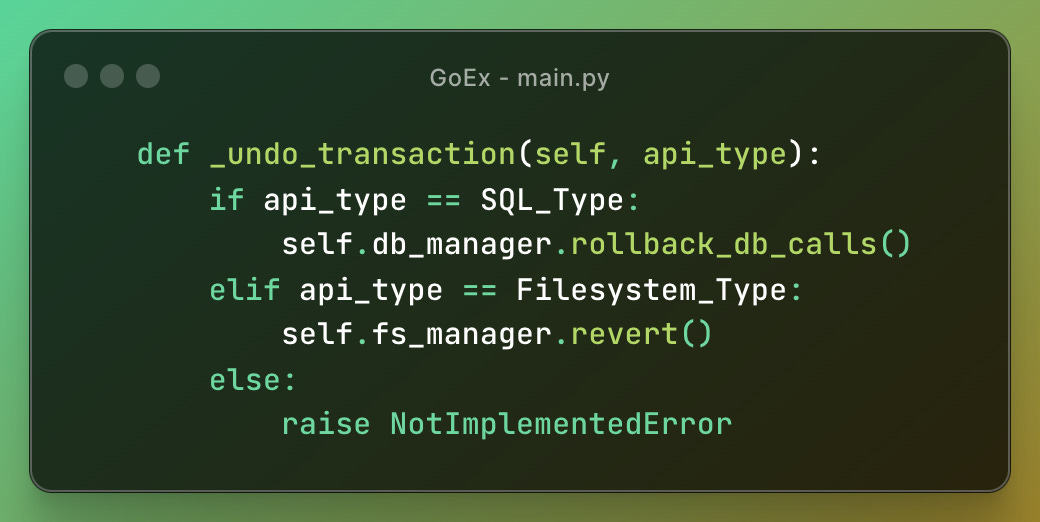
They have different undo mechanisms, for example, there is an _undo_transaction for SQL or filesystem APIs.
Conclusion
I have seen an idea like this for the first time and it was definitely worth reading the GoEx paper.
The problem of LLM-generated output is of huge importance and we need to overcome it if we want to move more autonomous AI agents and apps to an enterprise-grade level.
There are other ways to make running the potentially unsafe output secure. We can mitigate this risk by executing the generated code in a sandboxed environment, whether it be a container or a bare-metal VM.
Even running agents locally (e.g., with Docker) have limitations. Then there is the option to use a full VM environment, like the E2B sandbox, as it is adapted for LLM apps, and allows customization for different use cases.
The difference between the E2B approach and the GoEx approach is the stage of the whole workflow where the solution acts. While GoEx mostly provides a solution for reversing damaging actions and helps identify the risks, E2B provides a cloud where the actions happen in isolation from the user’s operating system, regardless of whether they are right or wrong.
I am happy to discuss your take on this in the comments. Thanks for reading!