


Which LLM is Really the Best?
Test them on any task in WebDev Arena for free & see the differences yourself


We have all seen many benchmarks comparing LLMs. If you’re an AI enthusiast, you have probably come across something like this:

…or this:

But how often do you actually get to see them perform in comparison?
Try WebDev Arena
WebDev Arena is an arena where two LLMs compete to build a web app. It’s free and very simple:
You write a task (e.g., “Build a productivity tracker” or “Build a photographer portfolio website”)
Two randomly chosen LLMs complete the task and show you the result
Without knowing which LLMs were competing, you voted for whatever result you liked better
You are revealed which LLM created which result.
This AI battlefield allowed me to finally see the models in comparison. It helped me verify what I had been thinking for a while - for example, that Claude Sonnet is really great. Or that Qwen Coder is surprisingly good at coding-heavy tasks.
How it works under the hood
WebDev arena is built with Next.js, Tailwind CSS, and AI SDK by Vercel. But most interestingly, it uses E2B to make the outputs from the LLMs actionable.
When the LLM is given a task (e.g. “Build AI data Analyst app”), it starts planning it and then generating the code needed for that. But how is the code transformed into the result? That’s where E2B comes. The code is automatically executed in the “E2B Sandbox” - an isolated cloud environment.

That way we can immediately see the result. The E2B Sandbox is a small isolated VM that can be started very quickly (~150ms). You can think of it as if the LLM had its own small computer in the cloud.
Moreover, you can run many sandboxes at once, in this case, a separate sandbox for each task.
Models competing
Right now, the WebDev Arena offers four different models competing against each other. Each time two of them are randomly chosen.
My results
There are no official results as far as I know, but I made my own little experiment.

I ran different prompts many times. Each LLM competing has its own row indicating how many times it won against LLM in each column. (And opposite, each column shows how many times the given LLM lost against LLM in each row.)
My experiment shows Claude as the clear winner.
Prompts I tested:
Create a copy of the Linear app
Create a LinkedIn profile of the cringiest AI influencer ever
Visualize an approximation of pi
Create calculator
Create a drawing program
Create a flight booking app
Build AI Data Analyst app
Build evals platform for AI agents
Design a dating app for programming languages
Build a personal finance tracker with budget visualization
Build an interactive periodic table
Design a galaxy exploration visualization
Create a task management system with a Kanban board
Selection of results:

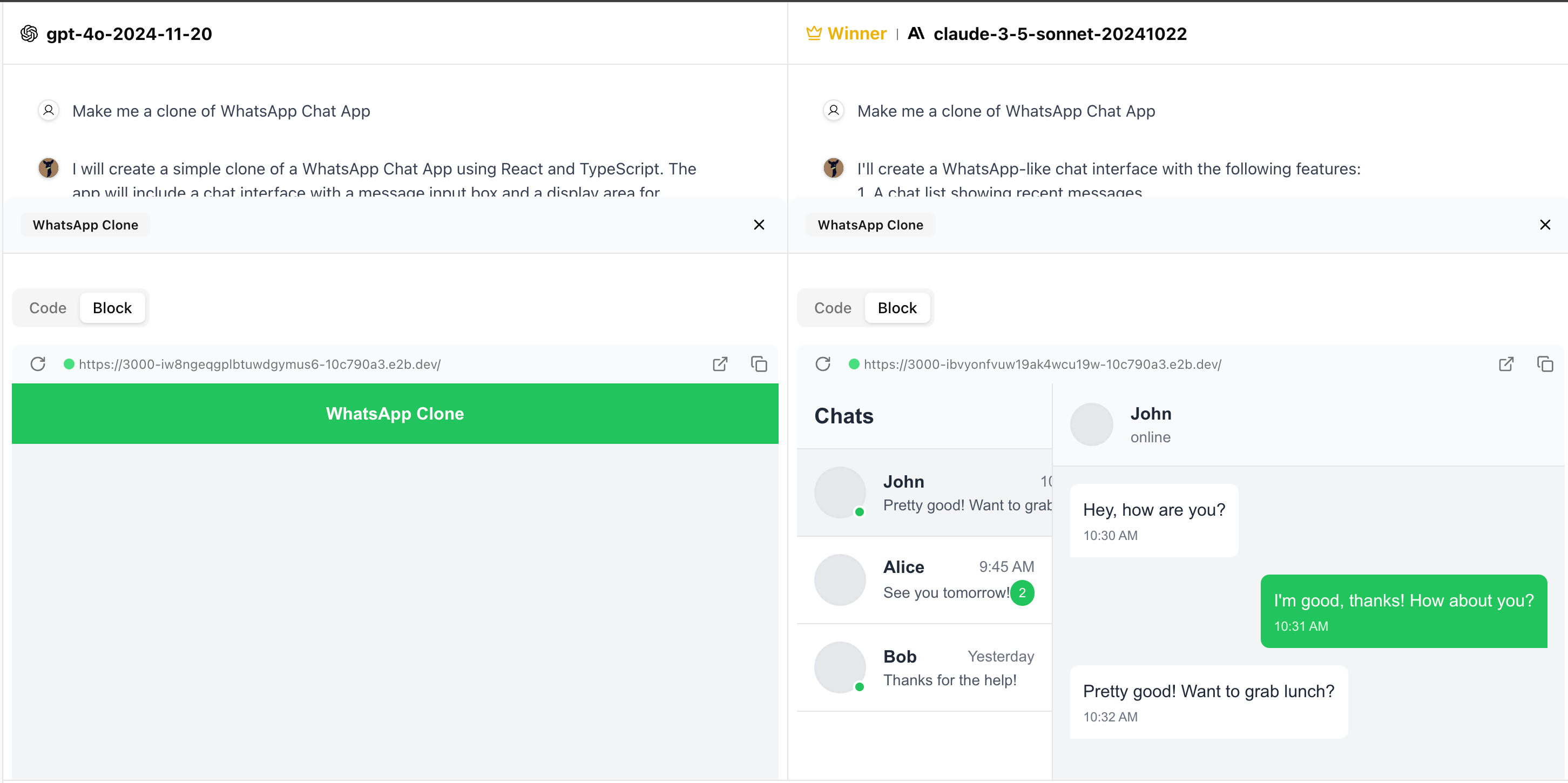




What do you think?
If you want to join the discussion or stay under for more content on this topic, here is my X and LinkedIn profile.
Follow also E2B on X and LinkedIn.